

In the first part of the article, which was released the other day, we conducted a measurement of the processing speed of "Metashape" in a cluster configuration of four machines with the same specifications, and examined its tendency. Based on the results, in the latter part of this article, we will examine the trend of "Priority of CPU core number" processing.
* The article on this page will be the second part.Click here for the first part
About the verification environment
The measurement isLast timeTo the same configuration based on the following cluster node, one specification with an increased number of CPU cores was added as a CPU node and implemented.
Cluster node
| CPU | Intel Core i9 9900K (3.60GHz / TB5.0GHz, 8C / 16T) |
| memory | 40GB |
| SSD | 1TB S-ATA |
| GPU | Geforce RTX 2080Ti x 1 |
| LAN | Onboard (1GbE) |
| OS | Microsoft Windows 10 Professional 64bit |
| Metashape | See 1.5.2.7838 |
The added CPU node has the following specifications. The number of CPU cores is 2 cores in a 16 CPU configuration, which is the highest class rated clock and TB clock configuration for 2 CPU Xeon specifications.
CPU node
| CPU | Xeon Gold 6144 (3.50GHz / TB4.20GHz, (8C / 16T) × 2 (total 16 cores) |
| memory | 768GB |
| OS | Microsoft Windows 10 Professional 64bit |
About processing contents
The processing I did this timeA series of batch processing of ortho image processingWill be. In this process,First partWith the sample data of Doll used in, it was difficult to distinguish the difference in the measurement results because the load was a little low, so we prepared and used the following data.

The processing contents are the same as the previous time, ①MatchPhotos ②AlignCameras ③BuildDepthMaps ④BuildDenseCloud ⑤BuildModel ⑥BuildUV ⑦BuildTexture.
As a measurement method, the machine with the above CPU node configuration is used as a node with the setting that uses only the CPU, and the priority of node processing is set to Highest. With this, the CPU processing in ⑤ Build Model to ⑦ Build Texture will be calculated in this node. However, please note that there is a slight difference in individual parts because the processing is assigned to this node when calculating with the CPU in other processing as well.
The processing on the Metshape side is performed with the following parameters.
Aligen Photos: Highest
Build Dense Cloud: Ultra High
Build Mesh: High field & High
Build Texture: Orthophoto
(This time, the process of Build Mesh is High quality. The reason will be described later)
About processing results
First is the result of calculating the total processing time from (XNUMX) Match Photos to (XNUMX) Build Texture.
| Cluster 1 (RTX 2080Ti × 1) | 4 hours 33 minutes 01 seconds |
| Cluster 2 (RTX 2080Ti × 2) | 3 hours 45 minutes 45 seconds |
| Cluster 3 (RTX 2080Ti × 3) | 3 hours 33 minutes 33 seconds |
| Cluster 4 (RTX 2080Ti × 4) | 3 hours 31 minutes 35 seconds |
| 4 clusters (RTX 2080Ti x 4) + CPU Node |
3 hours 17 minutes 09 seconds |
| Single system for comparison (RTX 2080Ti × 2) | 4 hours 16 minutes 33 seconds |
* For the specifications of the single unit system for comparisonFirst partPlease refer to
Next, we will verify each phase as in the first part.
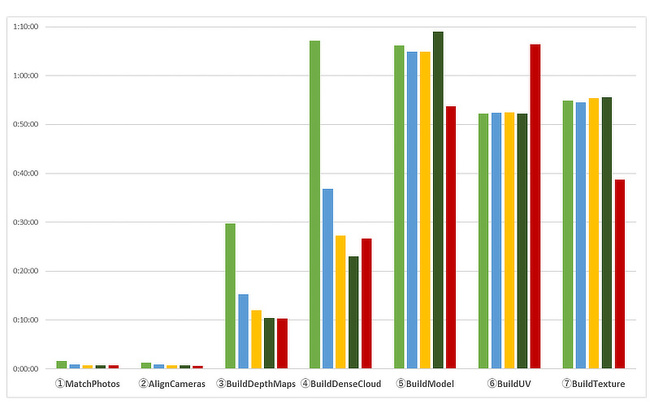
(Y axis = elapsed time: the longer the graph, the longer it takes to process)
#In the case of a single system, the log output is different, so it is not included in the above graph.
As expected, a big change was seen when a CPU node was added in the part of ⑤ Build Model ~ ⑦ Build Texture. When it is executed only on the same node, the processing time is side by side as before, but there was a difference due to the CPU node processing. The processing time for (XNUMX) Build Model and (XNUMX) Build Texture is shorter, and conversely, (XNUMX) Build UV is longer.
Here, again compare the CPUs of this cluster node and the CPU node.
Cluster node
| CPU | Intel Core i9 9900K (3.60GHz /TB5.0GHz 8C/ 16T) x 1 |
CPU node
| CPU | Xeon Gold 6144 (3.50GHz /TB4.20GHz 8C / 16T) x 2 (16 cores in total) |
Cluster node sideSingle core operates faster, On the CPU node sideMany coresIt becomes a relationship such as. From this, it can be inferred that ⑤ BuildModel and ⑦ BuildTexture time are processes in which the number of cores works effectively, and ⑥ BuildUV, the operating speed of a single core is important.
Also, regarding the processing time of ④ BuildDenseCloud, 4 nodes (4 clusters) Is taking longer than the result.This is because the processing is distributed to the CPU whose processing speed is slower than GPU processing as the number of CPU nodes increases, and even if the processing is completed on the GPU-equipped cluster node, the processing on the CPU side is not completed and the processing is performed. It is presumed that it was the result of waiting for it to finish.Actually, this process is divided into multiple processes on the log (about 106 to 108 in this verification), and when the process is completed, it is passed to the next process ..., so the final divided process ends. On the contrary, depending on the timing, the processing time may be faster.
Note that the cluster nodes this time have the same CPU / GPU configuration, but if they are built with different CPUs or GPUs, it is possible that slow CPUs or GPUs may become a bottleneck in this process. It is possible.
Finally, the reason why the Build Mesh process was not executed in Ultra High, which was mentioned in the item "Processing contents", is "Because it could not be executed". The memory of 1GB per cluster was not enough to process this data, and the process did not proceed.
In the case of a CPU node configuration (768GB) that has plenty of memory, processing was possible even with Ultra High, so for Build Mesh, processing is concentrated on one node, so sufficient memory is required for that one Is supposed to be.
Summary
The above is the verification result of the processing speed of Metashape using clusters.
Based on the data up to this point through the first and second parts, it seems that the cluster configuration is advantageous up to ④ BuildDenseCloud processing, but the subsequent processing is not so effective.
Also, as mentioned above, in the end, processing such as Build Mesh needs to be processed by one CPU, and that one also needs sufficient memory capacity. Even when considering the cluster configuration, considering the overall processing, there is a possibility that the required processing cannot be performed due to lack of memory, so prepare at least one PC with sufficient memory. I think it's okay to ask.
Even if you select a CPU with a fast independent clock, there is an upper limit to the memory capacity that can be installed, so in terms of the amount of memory installed, the Xeon system is more advantageous. For that reason, there are some places where we cannot simply say that a CPU with a fast independent clock is recommended.
* The CPU (Core i9 9900K) used for the verification this time supports up to 64GB of memory (as of April 2019. Future Rev will support 4GB).
When considering a Metashape cluster configuration under the present circumstances, the Metashape that is normally used individually is used as a cluster temporarily when large-scale processing is required, or a server farm that performs the work up to ④ BuildDenseCloud processing. It is possible to operate as.
In this verification, the main purpose was speed measurement, so we only performed one job, but of course it is possible to execute multiple jobs. In this case, when the process enters Build Mesh, the next job will start running if one machine other than the one being calculated becomes free, so you can throw multiple jobs and process them in a short time. It seems that the cluster configuration is also effective for such a purpose.


