

「AI」という言葉は、既にSFの世界の言葉ではなく一般的な技術として認知されるようになりました。
このAI=Artifical intelligence (人工知能) という言葉は、1956年に開催されたダートマス会議において初めて用いられた用語です。
近年、AI技術の発展に伴い、関連するキーワードとして、「機械学習」「ニューラルネットワーク」「ディープラーニング」といった言葉も目にする機会が増えています。
本記事では、これらの言葉はどのような関係があり、どのような技術・製品と関連があるのかをご紹介します。
機械学習ってどんなもの?
AIとは広義的に人工知能を指す言葉です。機械学習やディープラーニングなどの技術は、AIに内包されるカテゴリと言えます。
AIは、コンピュータ上で人間と同等の知能を完成させようという試みや技術を指すものです。
機械学習は、データを蓄積・トレーニングによって、特定のタスクをコンピュータ上で実施できるようになる仕組みです。
ディープラーニングは機械学習の1種で、十分なデータがあれば人間が手を加えなくてもコンピュータが自律的に予測や分類を行う仕組みです。人間が指示をしなくてもコンピュータが自動で学習し、精度を高めていく点に特徴があります。

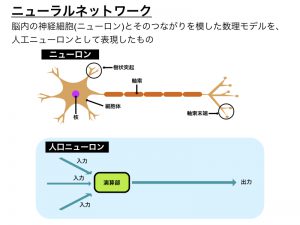
AIの歴史は古く、1943年にウォーレン・マカロックとウォルター・ピッツにより、ニューラルネットワーク理論 (形式ニューロン) が提唱されました。
このニューラルネットワークとは、脳の神経回路の特性を模した数理的モデルです。
1958年にはフランク・ローゼンブラットが視覚と脳の機能をモデル化しパターン認識を行うパーセプトロンを発表し、学習可能なネットワークについての研究が進められることになります。
1986年には、デビッド・ラメルハートらによって、機械学習においてニューラルネットワークを学習させる際に用いるアルゴリズムであるバックプロパゲーション (誤差逆伝播法) が開発されました。
それから30年ほど過ぎた2006年、ジェフリー・ヒントンらにより層ごとの事前学習が提案され、2010年にはディープラーニングという分野が形成されてきました。
そして現在では、さまざまな分野で、AI・機械学習・ディープラーニングの技術が活用されています。
機械学習の種類
前述の通り、機械学習とは多くのデータをコンピュータに学習させ、分類・予測など何らかのタスクを遂行するアルゴリズムやモデルを自動的に構築する技術を指す言葉として用いられます。
そして、機械学習はAIに内包されるカテゴリの1つであると同時に、AIの概念の中心的な位置を占めています。
機械学習という言葉自体も、複数の要素をまとめて指し示すものであり、大別するとに以下の3つの学習方法が存在します。
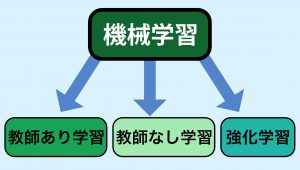
1.教師あり学習
予め質問 (入力データ) と人間が用意したその答えになるデータ (正解ラベル) が与えられます。このデータセットに対する予測値を正解ラベルに近づけることを目的とした学習方法が教師あり学習です。データの特徴を分析し、そのデータが正解である確率を判断します。
また、教師あり学習の扱う問題は「分類」と「回帰」に分類することができます。
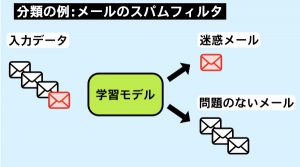
■分類の例
データが属するラベル (例:YES/NO、Aグループ/Bグループ) を予測することを目的とします。
(1) メールのスパムフィルタ
(2) ジェスチャー認識
(3) ドキュメント認識
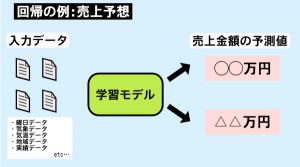
■回帰の例
数値を予測することを目的とします。データの関係性を推測し、正解を予測します。
(1) 株価予測
(2) 価格予測
(3) 気温予測
2.教師なし学習
学習データに正解を与えない状態で学習させる方法です。複数のデータから傾向や規則性を見つけ、共通する特徴ごとに分類します。
膨大なデータから相関関係を見つけることを得意とした学習方法です。
また、教師なし学習には「クラスタリング」「次元削減」といった手法があります。
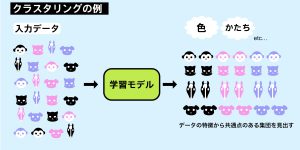
■クラスタリング
複数のデータから似た特徴の集まりを見出す手法です。
正解ラベルから判断するのではなく、データの特徴から共通点のある集団を見出します。
■次元削減
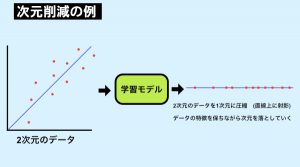
できるだけ情報を失うことなく、データの次元を減らす手法です。
機械学習で扱うデータは、高次元データである場合が多いです。
そのために可視化しにくく、直感的にデータ構造を理解することが難しい上、計算コストがかかります。
しかし、実際には変数同士に相関があったり、分析において重要となる変数は少なかったりするため、あまり情報を失わずに変数を減らすことができます。
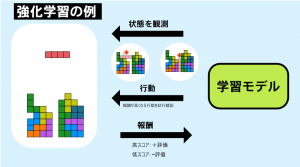
3.強化学習
ある選択肢の中で目的として設定された報酬 (スコア) を最大化するために、コンピュータ自身が試行錯誤を行う学習方法です。
コンピュータ囲碁プログラムの「AlphaGo」は、強化学習によって勝利パターンを学習したと言われています。
機械学習に必要なもの
初心者がAIを作るにはハードルがかなり高いため、APIやフレームワークを利用して開発するのが現実的かもしれません。
または、無料ツールを用いる方法もあります。Sonyが提供する『Neural Network Console』はプログラミングの知識がなくてもディープラーニングを行うことができます。Windowsアプリ版は無料で提供されており、クラウド版は有料です。ディープラーニングの入門編として、まずはこういったツールでイメージを掴んでみる方法もあります。
一方、本格的に機械学習でのAI開発を進める場合、プログラミング言語を用いて学習モデルを開発することになります。最近ではPythonやSQLなどを用いての開発が一般的です。
1.Python
近年、特に人気のあるプログラミング言語です。
Pythonについては、【特集記事】プログラミング言語 Python その人気の理由は?- Python プログラミングを加速するツールたちもご覧ください。
習得が比較的容易であることや、YouTubeやInstagramなど身近なサービスでも利用されているという信頼性の他、ライブラリやフレームワークが多数存在する効率性の高さなどから、機械学習のプログラミング言語として広く支持されています。
2.SQL
データベースを操作するための言語です。データベースに保存された大量の情報を効率的に操作する事ができるようになります。
AIの学習データを用意するには、学習に使用したいデータに手を入れて学習しやすいように加工する前処理と呼ばれる工程が必要になります。この前処理はAI開発の7~8割を占めるとも言われている非常に重要な作業であるため、SQLの知識が有用です。
また、学習用データを操る上では、データベースに関する知識も必要となります。
プログラミング関連のスキル以外には、学習のもとになるデータの準備や、処理を行うためのマシンが必要です。また、ディープラーニングの代表的な利用環境であるCUDA Toolkitのインストールも必要となる場合がありますので、コンピュータの導入に迷う場合には弊社TEGSYSのモデルPCや導入事例などをご覧いただければと存じます。
機械学習の流れ
機械学習はどのようなステップで行われるのかを見ていきましょう。 実際の作業では扱うデータや手法などによって細かな部分で差異があるかと存じますが、大きな流れとしては以下のとおりです。
1.データの準備
まずは、学習のもとになるデータを取得するところからのスタートです。
必要なデータ量は学習方法や学習内容によって異なりますが、平成31年時点での総務省による「AIへのデータ利用の状況」の資料の範囲では、10,000件以下の事例が2割近くを占めています。しかし、それ以上のデータを用いた事例も多数存在します。いわゆるビッグデータを処理するためには、膨大な量のデータを高速に処理できる環境が必要です。ただし、最近では転移学習などを用いて少量のデータでも学習できる方法が注目されています。
※転移学習:ある領域の知識を別の領域の学習に適用させる技術。
2.手法の選択と学習モデルの作成
どんな手法を用いて機械学習を行うか検討します。
データの規模や品質、課題の緊急性や利用目的、計算環境などに応じて、学習方法やアルゴリズムを決める必要があります。
3.前処理
収集したデータの中から、学習に必要となるデータを選別します。
一般的に、収集したデータをそのまま使うことは難しい場合が多く、データの欠損や不正なデータなどが存在する場合があるため、機械学習で使用できるように整える作業が必要です。SQLやデータベースに関するスキルが必要となる工程です。
4.パラメータのチューニングとトレーニング
機械学習のアルゴリズムを活用し、ネットワークの重み付けを変えていく工程です。
ディープラーニングのDeep Neural Networkにおいては、トレーニングプロセスの中である程度自動で設定されるものもありますが、中には学習を行う際に人間が予め設定すべきパラメータ (=ハイパーパラメータ) が存在します。例えば、ニューラルネットワークの層の数やユニットの数などは人間が設定する必要のある部分です。
ハイパーパラメータの値が最適になるまで、モデルの性能評価とトレーニング、チューニングを繰り返す必要があります。最近では、ハイパーパラメータの自動最適化ツールも存在するため、比較的簡単に調整できることもあります。
なお、ディープラーニングでは、ライブラリというツールの利用が一般的です。
特定の処理を再利用するために作られたツールであり、ライブラリを活用すれば自分で全ての処理をプログラムしなくても簡単に特定の処理を行うことができます。オープンソースとして配布されているものも多く、条件を満たせば自分でソースコードを改変したものを製品に利用することもできます。

■代表的なライブラリ
(1)Caffe/Caffe2
(2)Keras
(3)Chainer
(4)TensorFlow
(5)Torch/Pytorch
5.モデルの性能評価
分類モデルと回帰モデルで評価の指標が異なりますので、モデルの評価指標は1つではありません。
様々な評価指標から、どの指標でモデルを評価するのかが重要なポイントとなります。
■分類モデルの評価指標の例
分類モデルのトレーニング・性能評価でよく作成されるのが混同行列です。
各サンプルのクラス分け (AグループかBグループかといったもの) を予測するモデルの場合、予測結果と観測結果を比較する方法です。
混同行列は分類モデルの結果がどの程度の精度になるのかをわかりやすく示すことで、パフォーマンスの評価を行います。

・True Positive (TP) :実際にAグループに属するサンプルを、正しくAグループと予測できている状態。
・True Negative (TN) :実際にAグループではないサンプルを、正しくAグループでないと予測できている状態。
・False Negative (FN) :実際にはAグループのサンプルを、誤ってAグループでないと予測している状態。
・False Positive (FP) :実際にはAグループでないサンプルを、誤ってAグループと予測している状態。
(1) 正解率
全てのサンプルに関して、正確に予測できた割合

(2) 適合率
正解と予測されたもののうち、実際に正解だったものの割合
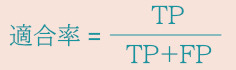
(3) 再現率
実際の正解サンプルのうち、正解と予測されたものの割合
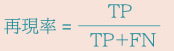
(4) F値
適合率と再現率をまとめた評価指標

■回帰モデルの評価指標の例
(1) 平均二乗誤差 (MSE) :誤差の二乗和の平均値で、MSEが小さければモデル性能が良い
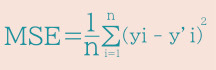
(2) 二乗平均平方根誤差 (RMSE) :MSEの平方根をとった値。値が小さいほどモデル性能が良い
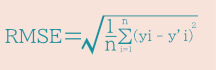
(3) 決定係数 (R2) :R2の値が1に近いほどモデル性能が良い
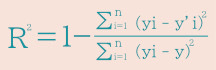
チューニング>トレーニング>評価を繰り返してモデルの精度を高めていきます。
これを繰り返しても精度が高まらない場合には、手法の選択まで戻って検討することも必要となります。
これらの流れを経て、AIの完成を目指すのが機械学習です。
上記はあくまでも一例であり、実際には異なるプロセスや更に詳細な工程が必要となりますが、大まかなイメージとしてお考えください。
機械学習に関連した製品
ここまでご紹介してきましたように、機械学習の導入が比較的容易になったことや関連技術の向上により、様々な場面で機械学習の成果が利用されるようになりました。
その流れを受け、機械学習をさらに快適な環境で行うためのPCやハードウェア、ソフトウェアが求められ、提供されています。
また、機械学習の成果を活用した製品なども増えており、従来製品からの機能向上やこれまでは実現の難しかった機能の実装など、研究開発シーンの更なる活性化に貢献していることは間違いありません。
以下は、弊社でお取り扱い実績のある商品のうち、機械学習に関連のある製品の例をピックアップしたものです。
これから機械学習を始める方、機械学習の具体的活用について興味をお持ちの方は是非ご覧ください。
なお、ここで取り挙げていない製品のお取り扱いにつきましても,お探しの商品がございましたらお気軽にご相談ください。
動物行動解析用マシン 事例No.PC-7984
ディープラーニングにより動物行動解析を行うソフト「DeepLabCut」のためのワークステーション構成例です。

RTX 3090×4搭載 4GPUマシン(100V電源環境向け) 事例No.PC-8351
RTX3090 x4枚によるディープラーニング向けマシン構成例です。

Coral Dev Board
IoTなどのエッジデバイス向けのGoogle Edge TPUを搭載したシングルボードコンピュータです。
TensorFlow Liteをサポートしており、システムオンモジュールにより、オンデバイス機械学習推論アプリケーションを施策することができます。

Orange Pi AI Stick
小型ボードコンピュータ Orange PiシリーズのAIスティック。
USBスティック型のモジュールをマシンに接続することで推論処理を実行することが可能です。

ポータブルFPGAアクセラレータ FLIK (FPGA Client Innovation Kit)
Intel製のFPGA「Intel Arria 10 GX FPGA」を搭載した、コンパクトなポータブルFPGAアクセラレータデバイス。
AI(人工知能)や計算集約型アプリケーションなどにおける、データ分析やディープラーニングなどの重要なワークフローを加速化します。

Duckietown
ロボット工学を学習できるオープンソースのAIカーです。
小さな疑似都市「Duckietown」で、自動車両(Duckiebot)を走行させ楽しくロボット工学、AI学習ができます。

Donkey Car
ラジコンカー向け自動運転プラットフォームキットです。
ラジコンカーなど小型自動車向けのオープンソースの自動運転プラットフォームで、AIと自動運転車を学ぶためのソリューションです。

ZED 2 Stereo Camera
高解像度の映像撮影が可能な3Dカメラです。
ステレオマッチング用のニューラルネットワークにより、 人間の視覚を再現し、立体と奥行の知覚をさらに向上させた新しいステレオカメラです。

MuJoCo
ワシントン大学で開発された物理エンジンです。
機械学習アプリケーションの並列サンプリングなどのモデルベースの計算実装に使用されます。
また、多関節の動力学シミュレーションに適しており、ロボティクス分野における制御シミュレーションにも活用されています。

Skeleton Tracking SDK License
ディープラーニングベースの 2D/3D スケルトントラッキング機能を、組み込みハードウェア向けのアプリケーションへ提供するよう設計されたソフトウェアです。行動判別などで活用できます。

メガネ型のアイトラッキングデバイス Pupil Invisible
Pupil Core を開発するPupil Labs 製のメガネ型視線追跡デバイス。
ディープラーニングを用いた視線推定パイプラインを採用しており、キャリブレーションの必要がなく、デバイスを装着しアプリで録画ボタンを押すだけで、視線 および 見ている風景のデータを同時に取得・記録します

BOOM Library DEBIRD
鳥のさえずりを自動的に検出し、除去するためのオーディオリペアツールです。
ニューラルネットワークにより、録音時に入り込んだ鳥の音を自動的に検出し、除去・抽出することができます。
鳥類音声、鳥のさえずりの学習などの研究用途にも利用できます。

まとめ
SDGsやSociety5.0など、理想とされる社会の中ではビッグデータの利活用が提唱されています。それによって幅広い分野、幅広いシチュエーションで、人々の暮らしが今以上に豊かになり、取り残される人のいない社会を目指した進化が加速していくことが予想されます。
従来と比較して、機械学習の研究環境は充実しており、幅広い研究分野で利用されています。その意味でも、AIや機械学習の技術は、持続可能な社会の実現に欠かせないものです。弊社でも、関連技術、関連商品の情報を発信・アップデートしていきますので、皆様の研究開発にお役立ていただけますと幸いです。


